基於PCA和PSO-SVM算法的雞精調味料風味質量模型研究
2021-08-26 15:17:42 來源: 世界杯賽程預測 導刊
程 龍,靳 濤,劉鳳蓮
(濱州市廚具產品質量檢驗中心,山東濱州 256600)
摘 要:目的:提出一種基於主成分分析和粒子群優化——支持向量機算法的雞精調味料風味質量模型。方法:以6種雞精調味料風味感官數據為研究對象,對雞精調味料的風味成分進行主成分分析,降低數據維數;利用粒子群優化算法獲取支持向量機的最佳參數,並用支持向量機完成對雞精調味料風味數據的訓練和分類。結果:本文提出的模型與其他傳統模型相比,具有較高的準確度,且實用價值高。關鍵詞:雞精調味料;PCA;PSO-SVM算法;支持向量機;質量控製模型
隨著人們生活水平的不斷提高,人們對美食的要求也越來越高。雞精調味料作為一種重要的食品調味料,其風味質量很大程度上決定了食品的口感[1]。傳統方法一般采用儀器分析和人工評吸的方式進行風味質量控製。但儀器分析獲得的數據隻能用來建立雞精調味料成分的風味數據庫,人工評吸的方式受品評人員的經驗限製,且主觀性強,費用高,不利於大批量數據的感官評測。
主成分分析(Principal Component Analysis,PCA)是多元統計中的一種數據挖掘技術。其主要用來將數據降維,在不丟失主要成分信息的前提下,選擇較少的變量來替代原有的變量,以達到數據冗餘的目的,加快運算速度。支持向量機(Support Vector Machine,SVM)是一種基於小樣本的模式識別算法,它不僅能夠克服傳統神經網絡對樣本大容量的要求,還能夠有效解決維數災難及局部最小值問題,並且在解決非線性問題上表現出色[2]。
雞精調味料組成成分複雜多樣,且存在非線性關係和大量的數據冗餘[3]。針對以上問題,本文提出了一種基於主成分分析(PCA)和粒子群優化—支持向量機(PSO-SVM)的雞精調味料風味質量模型。其中,PCA算法有效解決組成成分之間的數據冗餘,降低數據維數。PSO-SVM算法則解決傳統神經網絡複雜,對數據質量要求高的問題,且通過PSO算法的參數優化[4],SVM算法的分類識別效果更好。該模型能在有限的數據樣本訓練下,有效地對不同的雞精調味料進行分類,從而建立一個效果較好的雞精調味料風味質量模型。
1 基於PCA和PSO-SVM算法的風味質量模型
算法設計步驟如下:
①將雞精調味料樣本數據先進行歸一化數據預處理。這樣便於識別成分信息,避免出現“大數吃小數”的現象;②將經過歸一化處理的數據進行主成分分析,降低數據的維數,獲取一組線性無關的主成分來代表樣本的模式特征,樣本貢獻率要大於85%;③利用粒子群優化算法得到SVM的最優參數和,使得SVM的分類效果最佳;④將經過主成分分析後的數據導入SVM中進行訓練,並選取樣本進行預測分析。
2 實驗結果與分析
2.1 數據來源和試驗平台
本文數據來源於一組雞精調味料數據。樣本共有6種,樣本標簽名稱分別為K524、G101、G822、K365、K362和K862。每種雞精調味料有16個樣本,共96個樣本。將每種雞精調味料的前10個樣本用作SVM的訓練集,剩餘樣本作為測試集。即訓練集有60個樣本,測試集有36個樣本。
采用matlab2012a結合python2.7混合編程,並利用libsvm工具包模擬。
2.2 PCA分析
將雞精調味料數據作[0,1]歸一化後,利用Matlab對數據進行PCA分析,得到各主成分之間的特征貢獻率和累積貢獻率。
前兩個主成分的累計貢獻率約為92.66%,能夠包含原始數據的絕大部分的風味信息,所以選取第一和第二主成分作為新的變量來觀測分析。
2.3 PSO-SVM模型預測分類
由主成分分析可知,選取前兩個主要因素作為SVM的輸入,將60個樣本作為訓練集,36個樣本作為測試集。采用交叉驗證方式的準確率作為PSO的適應度函數值,尋找SVM的最佳參數值bestc和bestg。
SVM的核函數選擇上,選取徑向基核函數作為本文SVM的核函數。利用4種核函數做SVM分類(SVC)的最優超平麵(決策邊界)[5],如圖1所示。
為了進一步檢驗PCA和PSO-SVM模型性能的好壞,本文分別采用普通支持向量機分類器、基於PCA改進的支持向量機分類器以及BP神經網絡分類器(BPNN)進行對比分析,識別精度作為評價檢測模式性能優劣的標準,識別精度越高對應模型性能越好。4種不同模型的識別效果如表1所示。由表1可知,PCA和PSO-SVM分類器模型識別精度達到了98.87%,遠高於PCA-SVM分類器、支持向量機分類器(SVM)和BP神經網絡分類器(BPNN)。說明本文提出的基於PCA和PSO-SVM算法的雞精調味料風味質量模型分類預測效果良好。


本文提出的基於PCA和PSO-SVM算法的雞精調味料風味質量模型優勢體現在類別的選取上突破了很多文獻隻有2到3類的局限,選取了6種雞精調味料作為樣本。首先樣本數據進行歸一化預處理,接著用PCA對數據進行降維。然後使用PSO優化SVM的參數,選取RBF核函數作為SVM的核函數,得到一個分類率最高的SVM模型。並將模型的分類識別率與其他方法(如BP神經網絡、傳統SVM等)進行對比,結果表明本文方法具有更好的分類預測效果。該模型很好地克服了傳統雞精調味料風味分析方法中實時性差、可重複性差的缺點,為雞精調味料的風味質量控製提供了一種快速有效的方法。
參考文獻
[1]秦藍,李鳳華,田懷香,等.電子舌在雞精調味料味覺差異分析中的應用[J].中國調味品,2014,39(10):132-135.
[2]餘道洋,戚功美,瞿頂軍,等.基於SVM和PCA的痕量多組分氣體檢測方法[J].模式識別與人工智能,2015,28(8):720-727.
[3]秦藍,李鳳華,田懷香,等.雞精調味料人工感官評價與電子鼻感官分析的相關性研究[J].食品與機械,2014,30(4):11-13.
[4]胡旺,李誌蜀.一種更簡化而高效的粒子群優化算法[J].軟件學報,2007(4):861-868.
[5]吳桂芳,何勇.基於主成分分析和支持向量機的山羊絨原料品種鑒別分析[J].光譜學與光譜分析,2009,29(6):1541-1544.






熱點推薦
-
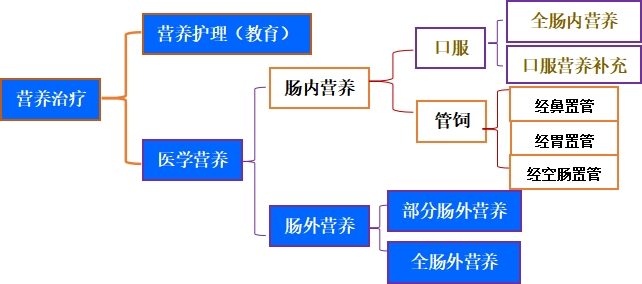
特醫食品不是藥,卻是臨床治療的關鍵支撐
- 世界杯2022赛程时间表最新
-

全十紅紅稗餅幹|中秋團圓,回家必備
-

和汪氏蜂蜜共同來普及蜂蜜結晶現象
-

拿坡海開啟西餐加盟新潮流, 大眾化家庭小西餐成未來新趨勢
-
基於PCA和PSO-SVM算法的雞精調味料風味質量模型研究
-
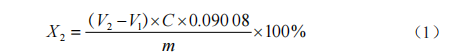
探析提高乳酸等食品添加劑的檢驗質量的方法
-
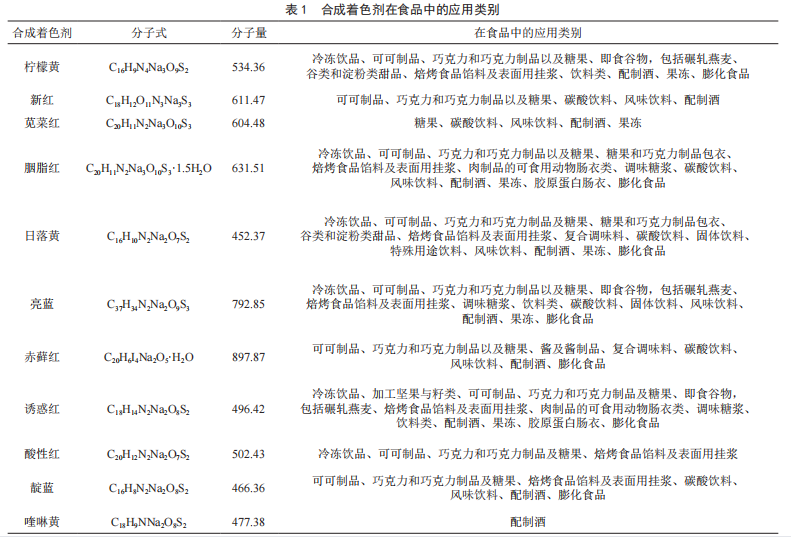
合成著色劑在食品中的應用及分析技術研究進展
-
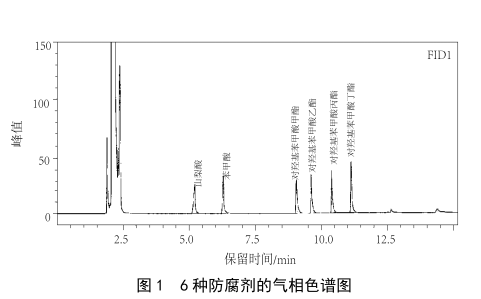
氣相色譜法快速測定醬油中的6種防腐劑
-
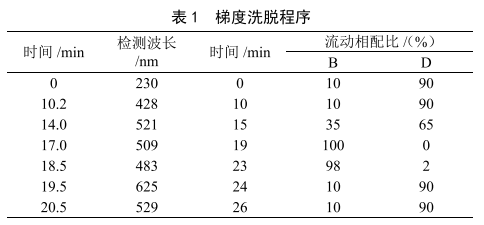
HPLC-DAD變波長梯度洗脫同時測定果蔬汁飲料中的9種食品添加劑
-

食品添加劑的真相,你應該知道
-
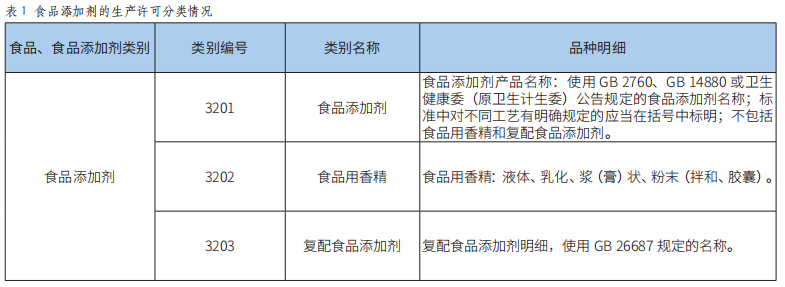
食品添加劑的生產工藝及現場核查要求
-

取自天然更健康,予之市場亦廣闊
-

科學證實體重能夠被有效管理
-
益生菌產品全球研發趨勢概述
-

從腸道健康到國民營養,蒙牛展現大健康戰略
-
取自天然的配料產品,助力運動型營養新突破
-

讓可食產品非法添加現形——阿裏健康聯手華測檢測製定最嚴“
-

護航“安全、健康和美味”,為產品天然化不懈努力
-

安全、健康、美味,做更好的香蘭素產品及解決方案
-

以繽紛科技倡導健康生活理念,致力創造更多可持續價值
-

BENEO將攜“運動型食品”亮相FIC 2019
-
益生元在體重管理領域的應用
-

以科學研究為首任,以用戶服務為中心
-

益生菌的蓬勃發展隻是時間問題
-

防腐劃重點—防腐劑的合理使用
-

Omega-3的攝入對母親和嬰兒有巨大好處
-
益生菌、益生元和Omega-3對情緒的影響
-

用創新思維開辟低聚木糖應用新領域
-
動物性食品中氯黴素殘留量檢測方法簡化及分析